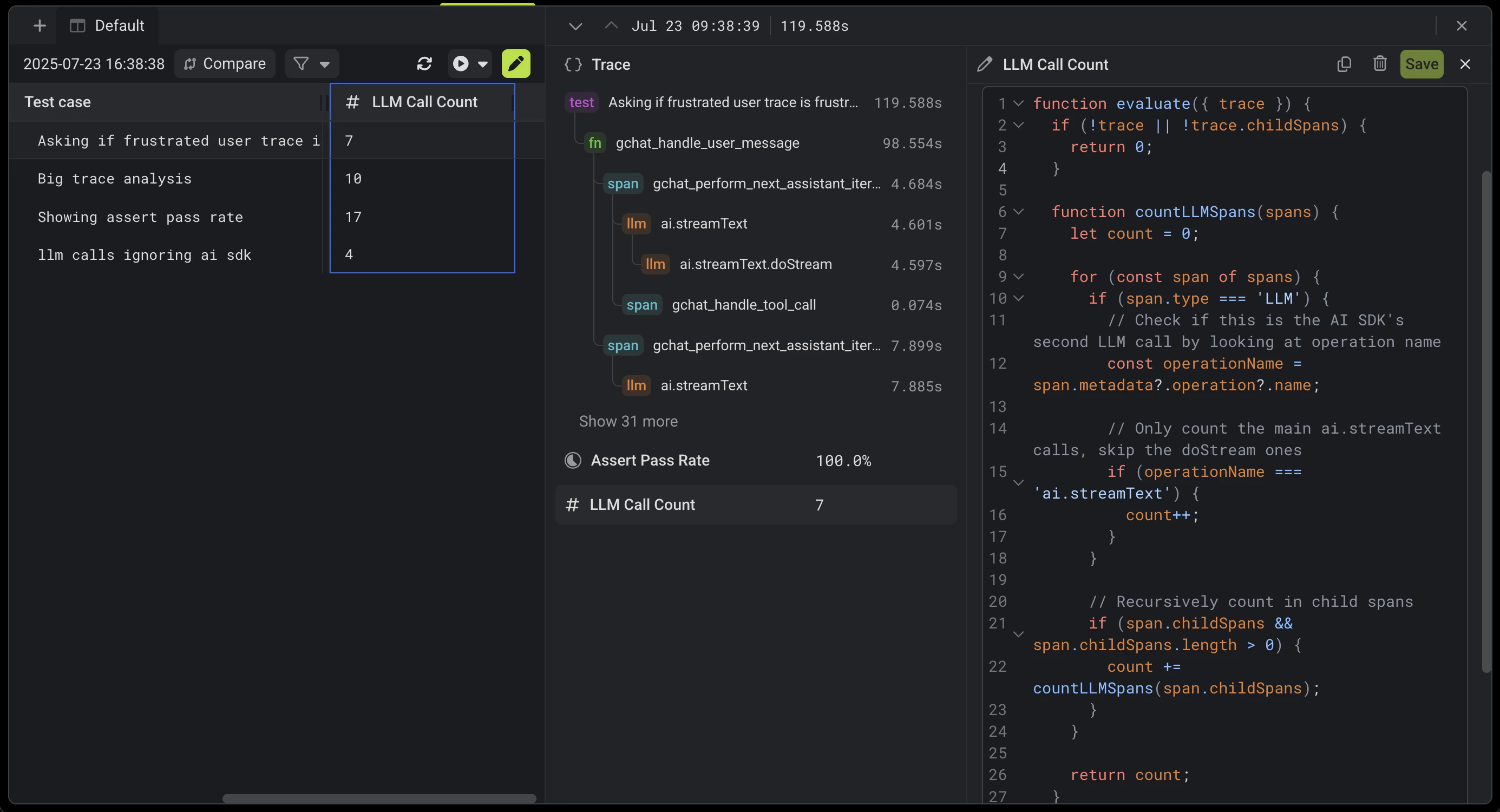
const { count } = await callAgent({
instructions: "How many r's in strawberry?",
jsonSchema: {
type: 'object',
properties: {
count: { type: 'number' },
},
required: ['count'],
},
});
// Analyzing a user message
const { sentiment } = await callAgent({
instructions: 'Analyze the sentiment of: ' + userMessage,
jsonSchema: {
type: 'object',
properties: {
sentiment: {
type: 'string',
enum: ['positive', 'neutral', 'negative'],
},
confidence: {
type: 'number',
minimum: 0,
maximum: 1,
},
},
required: ['sentiment', 'confidence'],
},
});
// Analyzing a trace
const { longestMessage } = await callAgent({
instructions:
'Get the sentiment of the longest user message in this trace',
resources: [{ type: 'trace' }],
jsonSchema: {
type: 'object',
properties: {
sentiment: {
type: 'string',
enum: ['positive', 'neutral', 'negative'],
},
confidence: {
type: 'number',
minimum: 0,
maximum: 1,
},
longestMessage: { type: 'string' },
},
required: ['sentiment', 'confidence', 'longestMessage'],
},
});